
AIの創造性は「均質」だった──22モデルで実証された同質化の構造
AIは人間より「創造的」かもしれない。だが、その創造性が全員同じ方向を向いているとしたら、それは本当に創造的と呼べるのだろうか。


AIは人間より「創造的」かもしれない。だが、その創造性が全員同じ方向を向いているとしたら、それは本当に創造的と呼べるのだろうか。
LLMの創造性テストで見えた不都合な事実
大規模言語モデル(LLM)の創造的出力は、人間の出力よりもはるかに均質である。デューク大学のエミリー・ウェンガーとイスラエル工科大学のヨエド・ケネットが、PNAS Nexus に2026年3月24日(現地時間)付で発表した研究が、この構造的な問題を数値で裏付けた。
研究チームは102人の人間と22種類のLLMに対して、心理学で広く用いられる3つの創造性タスクを実施した。ある物体の「代替的な使い道」をできるだけ多く挙げるAUT(代替用途課題)、互いにできるだけ異なる10個の名詞を考えるDAT(拡散連想課題)、そして連想思考を測定するFF(フォワードフロー)。テストされたモデルにはGemini、GPT、Llamaなど主要なLLMファミリーが含まれている。
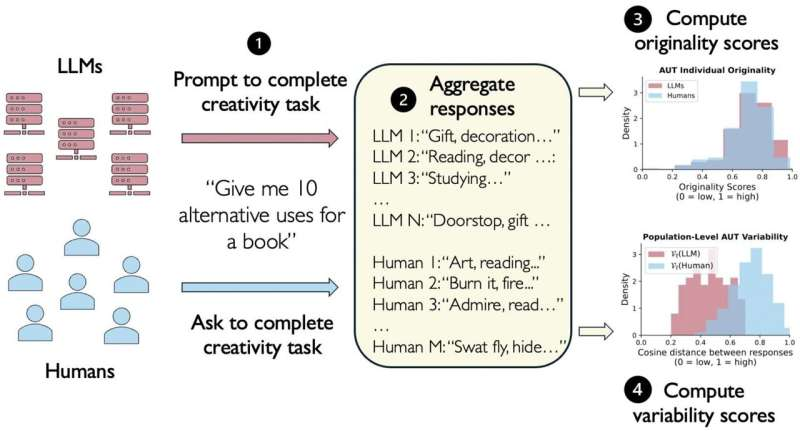
個別のスコアだけを見れば、LLMは人間と同等か、わずかに上回る。だが問題はそこではない。集団レベルの多様性を測定すると、LLMの回答同士は人間の回答同士よりもはるかに類似していた。AUTでは効果量1.8、FFでは0.87、DATでは1.1と、いずれも統計的に有意な大きな差が確認されている。
ひとことで言えば、AIは「賢い答え」を出すが、22のモデルが揃って同じ「賢い答え」に収束する。100人の人間に聞けば100通りの道が開けるところを、100のAIに聞いても数本の道しか見えない。
なぜモデルを変えても多様性は生まれないのか
この均質性は特定のモデルに起因するのではなく、LLMという技術そのものの構造的特性である。研究チームはLlamaファミリー(8B、70B、405B等)内での応答多様性も検証したが、同一ファミリー内ではさらに多様性が低下する傾向が見られた。異なる企業の異なるモデルを使っても、出力は似通う。
この現象の背景には 「特徴空間の普遍性」 がある。近年の研究で、異なるLLM間でも内部の特徴表現が驚くほど類似していることが報告されている。訓練データの重複、アーキテクチャの収斂、そしてRLHF(人間のフィードバックによる強化学習)による「好ましい回答」への最適化。これらが重なり合って、モデルの出力空間を狭めている。
語彙レベルの分析でも、LLMの回答間で共通する単語数は人間の回答間よりも圧倒的に多かった。人間は同じ課題に対して異なる語彙、異なる構文、異なる発想のフレームワークを使う。LLMにはその「ばらつき」がない。
temperatureを上げれば解決するのか
temperatureの引き上げは、LLMの創造的均質性に対する有効な解決策にならない。生成時のランダム性を制御するこのパラメータを0.5から2.0まで段階的に変えた検証で、多様性の向上と出力品質の崩壊がトレードオフの関係にあることが明らかになっている。
temperatureを上げると確かに統計上の多様性は改善するが、2.0ではほとんどの回答が意味不明な文字列になった。研究チームは非英語単語の除去や重複出力の排除といった前処理を行ったうえでなお、実用に耐える品質を維持できなかったと報告している。
システムプロンプトの工夫も試みられた。「あなたは創造的なアシスタントです」から「このテストで最高得点を取れば200ドル報酬があります」まで、段階的に創造性を促すプロンプトを設計。個別の創造性スコアはわずかに向上したが、集団レベルの多様性はほとんど改善しなかった。
つまり、AIに「もっと独創的に」と頼んでも、全員が同じ方向に「もっと独創的」になるだけだ。
「思考の均質化」は創造性だけの問題ではない
この研究は、2026年3月に相次いで発表されたLLMの均質化に関する警告のひとつに過ぎない。南カリフォルニア大学のジヴァー・ソウラティらは、Trends in Cognitive Sciences 誌で130以上の研究を分析し、LLMが言語、視点、推論のすべてにおいて人間の認知的多様性を圧縮していると論じた。
「個人はそれぞれ異なる書き方、考え方、世界の見方を持つ。それが同じLLMを介した瞬間、言語スタイルも視点も推論戦略も均質化され、ユーザー間で標準化された表現と思考が生み出される」
ソウラティの指摘は、LLMを直接使わない人々にも波及効果があるという点で重要だ。周囲の人間がLLMの文体や論理構造を内面化すれば、それに合わせる社会的圧力が生まれる。
・ ・ ・
2024年の先行研究では、GPT-4を使って創作した作家群の物語は、個別には創造性が高いと評価されたが、作家間の物語の多様性は大幅に低下した。大学入試エッセイの比較研究でも、GPT生成のエッセイは新しいアイデアの貢献度が人間より低く、均質化が確認されている。今回の研究が加えた新しい知見は、この問題が特定のモデルではなくLLMという技術全体に内在するという点だ。
AIを「創造的パートナー」にすることの代償
Adobeの2024年調査では、アメリカ人の半数以上がブレインストーミングや文章作成にAIを使っていると回答した。LLMユーザーの圧倒的多数が「AIは自分をより創造的にしてくれる」と信じている。
だが、この研究が示すのは正反対の可能性だ。LLMに依存すればするほど、異なるユーザーの出力が収束する。しかも使うモデルを変えても状況は変わらない。研究者たちは、LLMには身体も経験も意図も個性も理解もないと指摘する。これらの一部または全部が、人間の創造性をシミュレートするために必要かもしれない。
ここで立ち止まって考えるべきことがある。この記事を含め、AIが関与するテキストは増え続けている。AIが均質化を生むなら、AIが生成したコンテンツで訓練された次世代のAIは、さらに均質になるのではないか。フィードバックループの先に待つのは、多様性の緩やかな死かもしれない。
それでも、この問題に気づいていること自体が、まだ人間の側に残された強みだ。
参照元
他参照
#AI創造性 #LLM #大規模言語モデル #AIと人間 #創造性研究 #均質化 #認知科学 #情報の灯台



