
IntelのTSNC、テクスチャを最大18倍圧縮へ
テクスチャはゲームで最もVRAMを食うリソースだ。そこにIntelが、ニューラル圧縮技術「TSNC」で正面から殴り込みをかけてきた。

テクスチャはゲームで最もVRAMを食うリソースだ。そこにIntelが、ニューラル圧縮技術「TSNC」で正面から殴り込みをかけてきた。
従来比最大18倍──Intelが本気で取り組む圧縮技術
IntelがTSNC(Texture Set Neural Compression)の新たな詳細を公開している。GDC 2025でIntel Labsの研究デモとして初めて披露されたこの技術は、ニューラルネットワークを使ったテクスチャ圧縮だ。単なるプロトタイプから、スタンドアロンのSDKとデコンプレッションAPIを備えたプロジェクトへと進化しつつある。
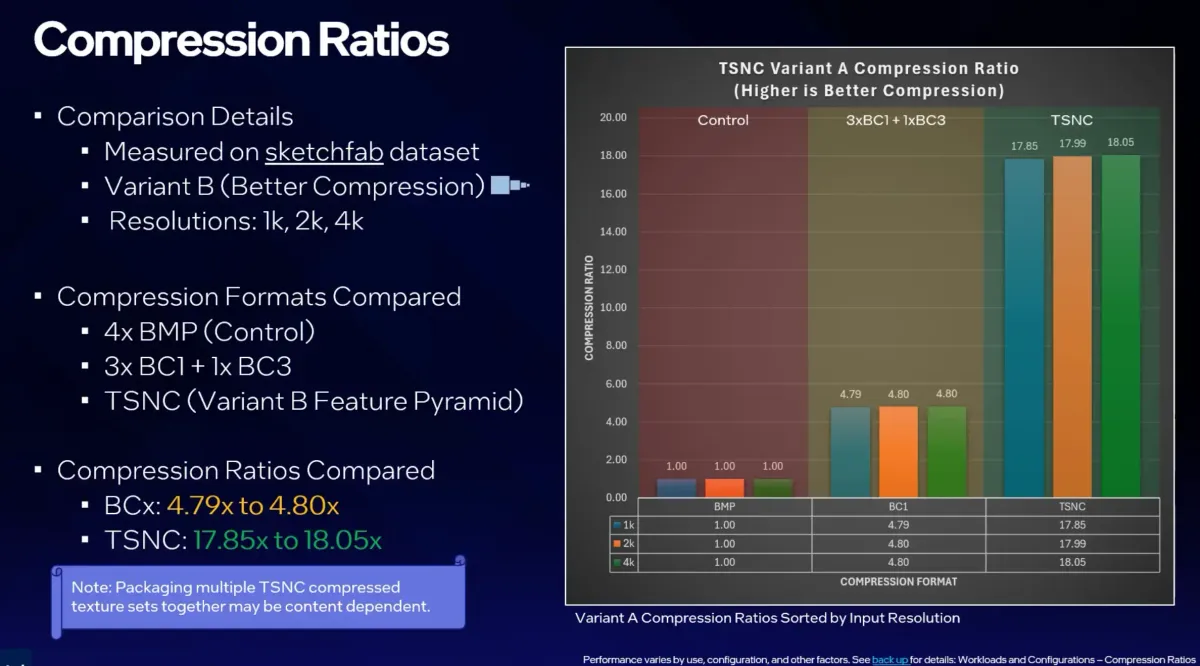
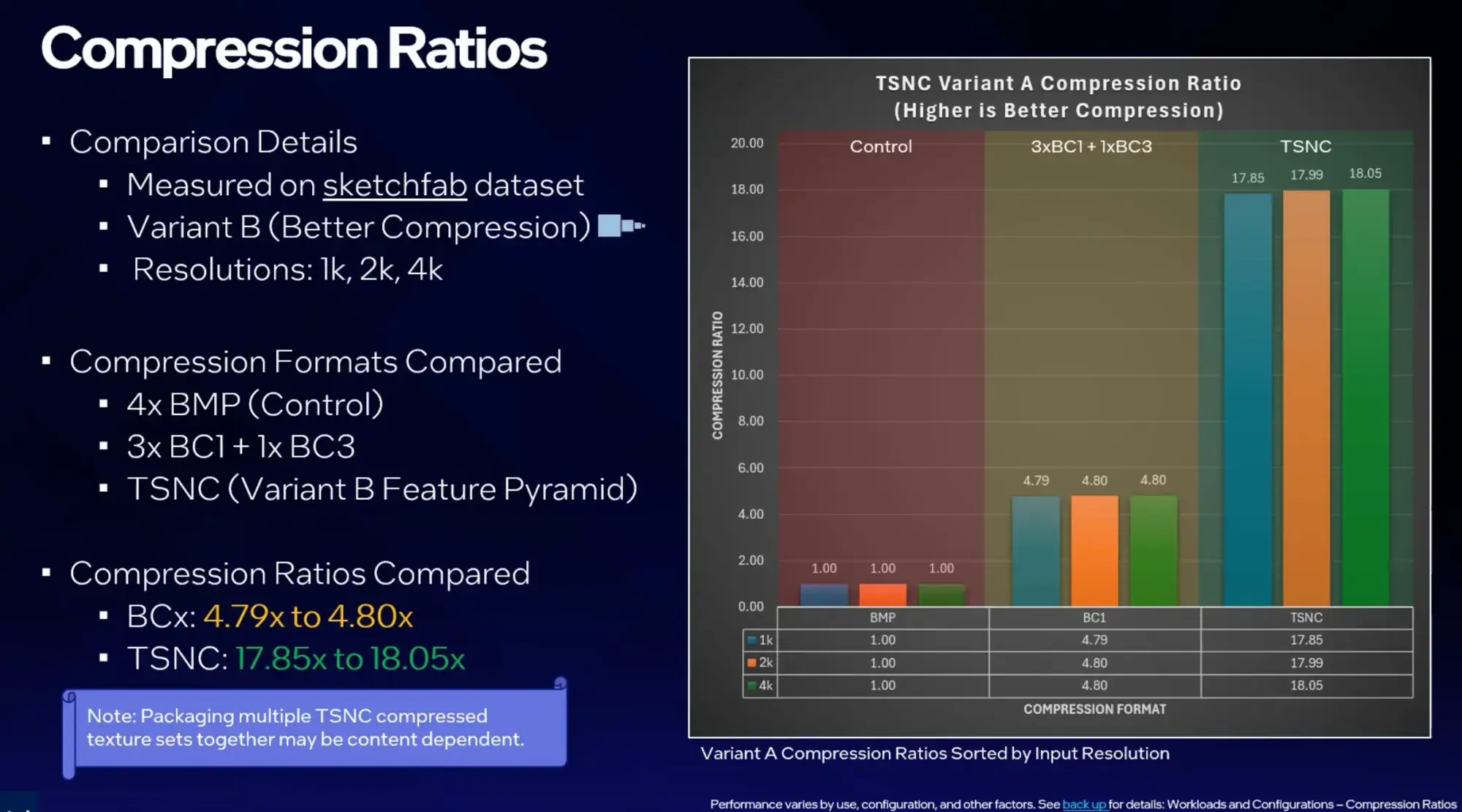
注目すべきは圧縮率の数字だ。Intelの自社テストによれば、従来のBCブロック圧縮がビットマップ比で約4.8倍の圧縮率にとどまるのに対し、TSNCのVariant Aは9倍以上、Variant Bは18倍以上の圧縮を達成している。同じテクスチャが5分の1以下に縮む。
Intel
ただし、この圧縮率と画質はトレードオフの関係にある。Variant Aは品質重視で知覚損失が約5%(NVIDIAのFLIPツールによる評価)、Variant Bは圧縮重視で6〜7%の損失が生じる。法線マップやARMデータではブロックアーティファクトが出始めるという報告もあり、Variant Aが現実的なバランスポイントになりそうだ。
TSNCはPBRテクスチャセット(アルベド、法線マップ、ラフネスなど最大9チャンネル)をまとめて1つのニューラルネットワークで圧縮・展開する。個別のテクスチャではなく「マテリアル全体」を対象にする点が、従来のブロック圧縮との根本的な違いだ。
ニューラル圧縮の仕組み──BC1の上に「学習層」を載せる
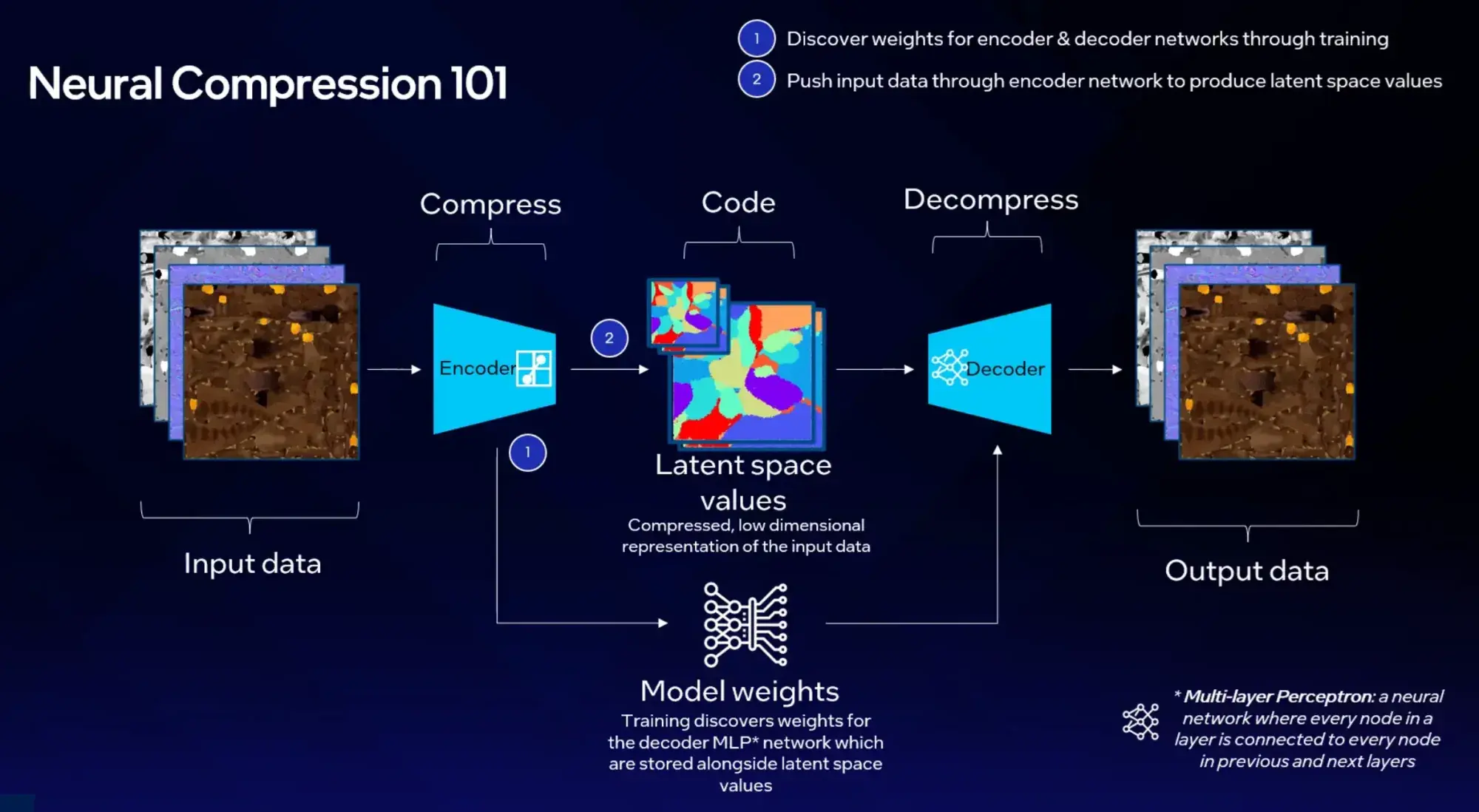
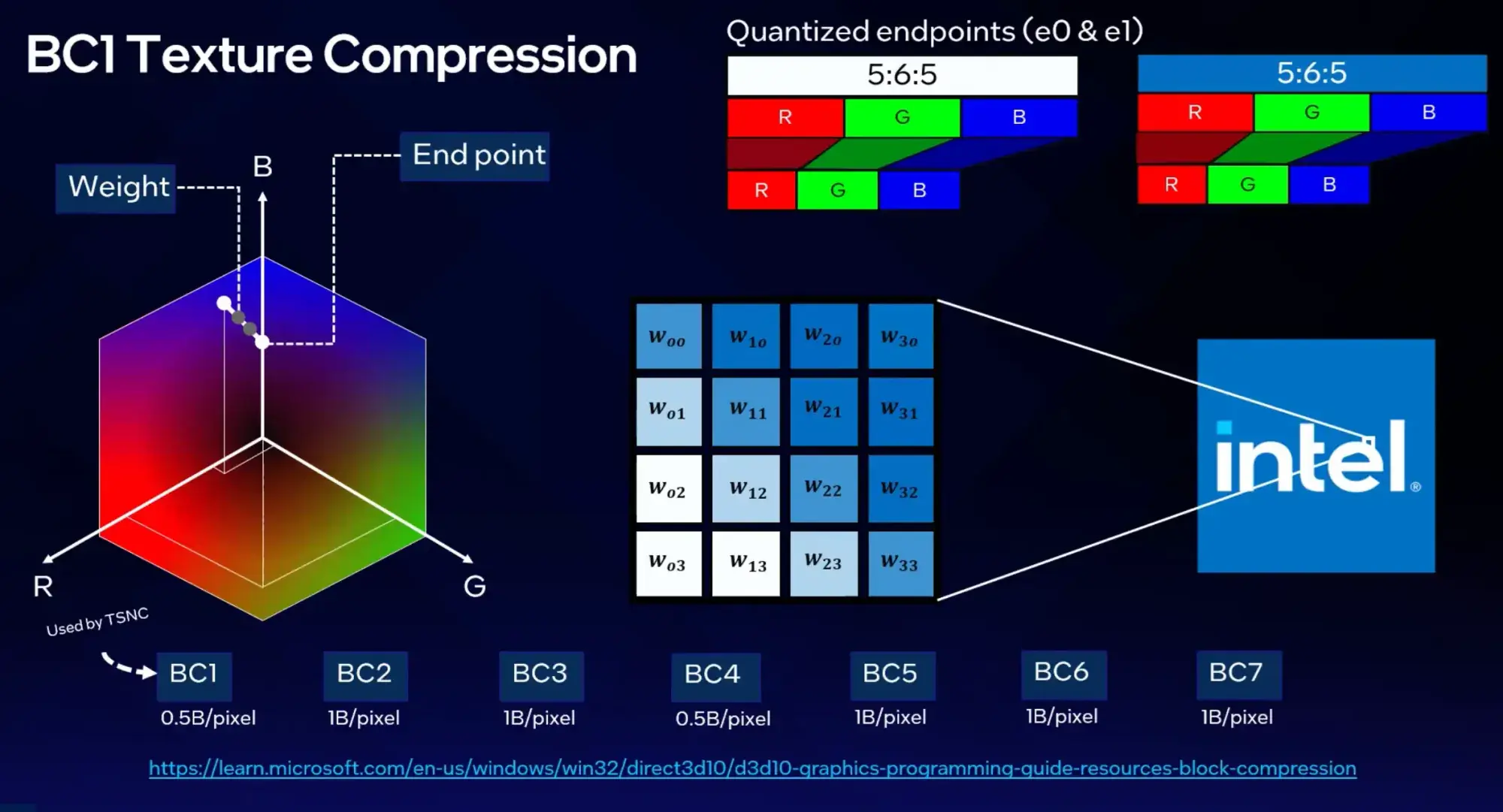
TSNCの技術的な核心は、既存のBC1ブロック圧縮フォーマットの上にニューラルネットワークの学習表現を重ねるアーキテクチャにある。テクスチャデータをエンコーダで圧縮し、潜在空間の値としてBC1ベースのフィーチャーピラミッドに格納。デコード時には3層のMLPがその潜在表現からオリジナルのテクスチャを再構成する。
MLP(多層パーセプトロン)は、すべてのノードが前後の層と全結合したニューラルネットワークだ。TSNCでは、このMLPがテクスチャごとに最適化された「辞書」として機能し、圧縮された潜在コードから元のピクセル値を復元する。
この設計の巧妙さは、BC1というハードウェアテクスチャフィルタリングに対応した既存フォーマットを「入れ物」として利用している点にある。GPUの既存テクスチャサンプリングパイプラインがそのまま使え、桁違いの圧縮率と既存パイプラインの互換性を両立させている。
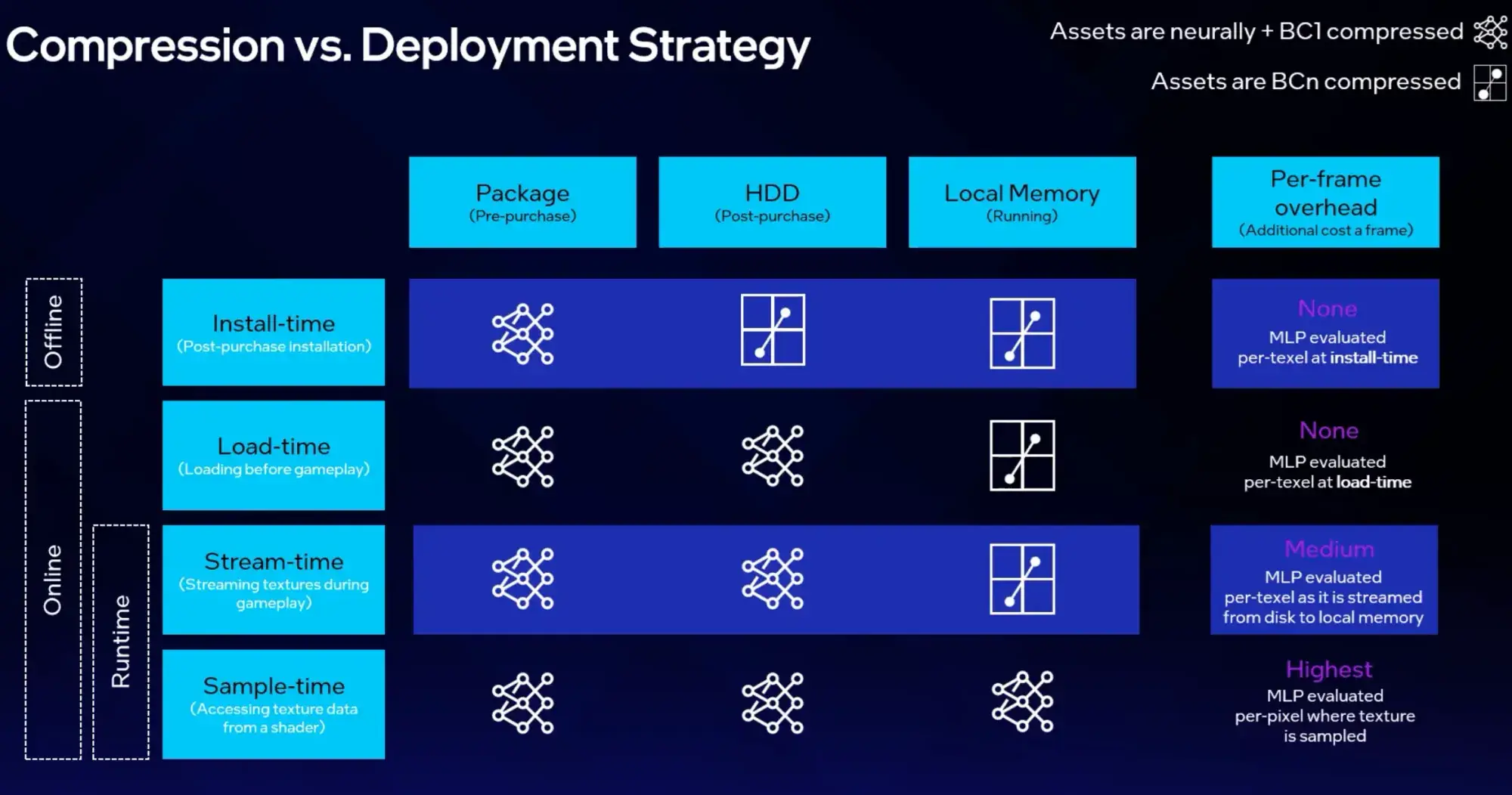
デコーダはC、C++、HLSLにコンパイル可能で、CPUとGPU両方のフォールバックパスを持つ。Intel GPUのXMXユニット(行列演算エンジン)によるハードウェアアクセラレーションにも対応しており、DirectX 12のCooperative Vectors機能をフルに活用できる設計だ。
Panther Lakeで走るマイクロベンチマーク
Intelは次世代iGPUであるPanther Lake内蔵のB390グラフィックス上でTSNCのマイクロベンチマーク結果も共有している。フォールバックのFMA(Fused Multiply-Add)パスが1ピクセルあたり平均約0.661ナノ秒、リニアアルジェブラ(線形代数)パスが約0.194ナノ秒。XMXによるハードウェア支援で約3.4倍の高速化を叩き出している。
この数字が意味するのは、TSNCが統合GPUでも実用的な速度で回るということだ。Panther LakeのArc B390は12基のXe3コアとXMXエンジンを搭載している。ハイエンドdGPU向けの技術を薄型ノートの内蔵GPUで動かす──Intelはそこを本気で狙っている。
さらに、Arc B580での実測データも論文で公開されている。4Kテクスチャセット(9チャンネル)を異方性フィルタリング付きで1080pレンダリングした結果、テクスチャセットあたりわずか28MBのVRAMで処理時間は0.55ミリ秒だった。
従来のBCn圧縮では同じテクスチャセットに数百MBのVRAMが必要になる。28MBという数字は、メモリ帯域が限られた内蔵GPUでもニューラルテクスチャ圧縮が実用域に入ることを示している。
NVIDIAも別ルートで同じ山を登っている
テクスチャのニューラル圧縮はIntelの独壇場ではない。NVIDIAはGTC 2026で自社のNTC(Neural Texture Compression)を再びデモし、Tuscan VillaシーンでBCN圧縮時に6.5GBだったテクスチャVRAM使用量を、NTCで970MBまで削減してみせた。85%の削減だ。
両社のアプローチには設計思想の違いがある。NVIDIAのRTXNTC SDKはバージョン0.9に達しており、NVIDIA GPUで最も高いパフォーマンスを発揮する。Intelは逆に、DirectX 12のCooperative Vectorsという標準APIに乗る形で、GPUベンダーに依存しない設計を選んだ。どちらが正解かはまだ誰にもわからないが、ゲーム開発者が「ベンダーごとに別のテクスチャアセットを用意する」なんて馬鹿げたことをやるはずがない以上、標準API側に収束していくのは時間の問題だろう。
ゲーム開発者の視点で言えば、特定ベンダーのGPUに最適化されたアセットを個別に用意するのは非現実的だ。グラフィックスエンジニアのセバスチャン・アールトネンは「ニューラルテクスチャ圧縮は良いアイデアだが、問題はオープンソースではなく、すべてのGPUで動かないことだ」と端的に問題を突いている。MicrosoftがDirectXの標準機能としてCooperative Vectorsを整備したのは、まさにこの問題への回答だ。
| Intel TSNC | NVIDIA NTC | |
|---|---|---|
| 圧縮方式 | BC1ピラミッド + 3層MLP |
潜在特徴量 + MLP |
| SDK状態 | α版(年内予定) | v0.9 ベータ |
| 標準API | DX12 Cooperative Vectors |
DX12 CoopVec + Vulkan |
| デモ実績 | 4K 9ch → 28MB 0.55ms(B580) |
6.5GB → 970MB 85%削減 |
| 対応GPU | Intel Arc (A/B/内蔵) |
NVIDIA / AMD / Intel Arc |
| ゲーム採用 | — | ほぼなし |
期待と現実のあいだにある溝
正直に言えば、この技術にはまだ大きな課題が残っている。NVIDIAがニューラルテクスチャ圧縮のコンセプトを初めて披露してから3年近くが経過したが、実際にこの技術を採用して出荷されたゲームタイトルは、Assassin's Creed Mirageを除けばほぼ存在しない。
Intelはアルファ版SDKを年内にリリースし、その後ベータ、パブリックリリースへと段階的に進める計画だとしている。NVIDIAのRTXNTC SDKはすでにバージョン0.9に達しており、AMD・Intel GPUでも動作する。技術の駒は揃いつつある。足りないのは、ゲーム開発者がこれを実際のタイトルに組み込むかどうかだ。
ゲームのインストールサイズは80GBを超えることが珍しくなくなり、VRAMの逼迫はRTX 5060のような8GB GPUで日常的な問題になっている。ニューラルテクスチャ圧縮は「AIスロップ」ではない。ジェネレーティブAIとは違い、開発時にオリジナルテクスチャで学習した専用ネットワークが忠実に復元する技術だ。ハルシネーションの入り込む余地がない。
それでも、ゲーム開発者がこの技術を採用するまでには時間がかかる。ドライバレベルで勝手に適用できるものではなく、ゲームエンジンへの統合が必要だからだ。そしてその頃には、あなたのGPUはもう次世代のものに変わっているかもしれない。
技術は揃った。足りないのは、それを使う側の決断だけだ。
参照元
関連記事
- DLSS 5の陰で、NVIDIAがVRAMを85%削減する
- NVIDIAがシェーダー問題に着手──自動再ビルドの実力は
- NVIDIA Pascal 10周年──黄金時代はどこへ
- Apple Silicon初のeGPU承認——NVIDIA対応だがAI研究限定
- GPUメモリ経由でPC完全掌握、新型Rowhammer攻撃の衝撃
- NVIDIA 3D Vision 2グラスがリサイクルショップで480円——2011年の夢の遺物、今も語り継がれる
- FSR 5「Scarlet Cortex」は幻か——4月1日の罠
- Intel「Wildcat Lake」全6モデルの仕様が流出──格安PCの景色が変わる
- DLSS 4.5が本日提供開始──「動的フレーム生成」と6Xモードの意味
- PNYの神対応──故障したRTX 5070が上位モデルで返ってきた



