
GitHub、4月に2件の連続障害でCTOが謝罪と説明


数千のプルリクエストが誰にも気づかれずに改ざんされ、検索が落ちた。CTOが新たに公開した謝罪文と再建計画は、GitHubが今どれほど追い詰められているかを浮き彫りにする。
CTOの謝罪は何を意味するのか
GitHubの公式ブログに、4月28日付でCTOヴラド・フェドロフ(Vladimir Fedorov)名義の投稿が公開されている。タイトルは「GitHub可用性に関する最新情報」。文中で同氏は、4月23日と4月27日に発生した2件のインシデントについて「容認できるものではなく、影響を受けた皆さんに申し訳なく思う」と書いている。
CTOがブログ記事の冒頭で謝罪文を置く判断は、GitHubがこれを軽く扱えなかったことを意味する。
このブログ投稿が出た背景には、2件のインシデントを巡って噴き出した強い不満がある。プルリクエストは「マージしたはずの変更が消えた」と気づいたとき、すでに終わった話を巻き戻すしかない。検索は、ボットネットからの攻撃と推定される負荷で機能停止に追い込まれた。GitHub自身が想定し切れていなかった2つの破綻が、わずか4日のあいだに重なったかたちだ。
4月23日、マージキューが誰にも気づかれずコードを書き換えた
4月23日のインシデントは、可用性の問題ではない。プルリクエストの マージ結果が間違っていた という、性質の違うものだ。
GitHubの説明によれば、UTC16:05から20:43の約4時間38分にわたり、マージキューを使って「スカッシュマージ」方式で取り込まれたプルリクエストが、複数のマージグループに含まれていた場合に誤ったマージコミットを生成していた。直前にマージ済みだった変更が、後続のマージによって意図せず取り消されていたのだ。
スカッシュマージとは、機能ブランチで重ねた多数の小さなコミットを1つにまとめてからメインブランチへ統合する手順を指す。マージキューはその統合を順番に処理する仕組みだ。両者を組み合わせて使っていた利用者だけが、この欠陥を踏んだ。
問題は、表面的には何も起きていないように見えたことだ。プルリクエストのページは「merged(マージ済み)」と表示されていた。CIは緑だった。ブランチ保護のチェックも通っていた。それでも、メインブランチに残ったツリーが、テスト時に検証された内容と一致していなかった。
4月23日、プルリクエストでマージキュー操作に影響する不具合が発生した。複数のプルリクエストが含まれるマージグループにおいて、スカッシュマージで統合された場合に誤ったマージコミットが生成された。影響を受けたのは230リポジトリ、2,092プルリクエストで、当初の発表値は意図的に保守的な見積もりだった。
——GitHub公式ブログ「An update on GitHub availability」より要約
GitHubは公式声明の中で、当初発表していた影響範囲を改訂している。ブログ末尾の「Editor's note」によれば、4月28日の更新でリポジトリ数の修正が行われた。当初は658リポジトリと公表していたが、現在のブログ本文では「230リポジトリ・2,092プルリクエスト」に書き換えられている。COOカイル・デイグルが直後にX上で出した数字も「 2,804プルリクエスト 」で、現在のステータスページや更新後ブログとは食い違ったままだ。
数字が二度三度書き換わるのは、GitHubが障害の規模を把握しきれていなかった、という証左だ。被害範囲が縮小したこと自体は良い知らせだが、初動の数字がここまで動くと、ユーザー側はどの瞬間の発表を信じればよいのか迷う。
一番危険なのは、ユーザーが先に気づく障害
このインシデントには、ふたつの特に重い意味がある。
ひとつは、GitHubの自動監視がこの破綻を発見できなかったことだ。問題のコードは16:05 UTCにデプロイ完了しているが、GitHubが事態を認識したのは19:38 UTC。3時間33分にわたって、誰も気づかないまま稼働し続けた。発覚の引き金は、自動アラートではなく顧客サポート問い合わせの増加だった。
サポート問い合わせの増加を受けて状況を把握した。マージコミットの正しさは可用性ではなく正確性の問題であり、既存の自動監視では検知できなかった。
——GitHubステータスページ事後分析より要約
もうひとつは、フィーチャーフラグでガードしているはずの未公開機能が、ガードを完全には効かせられないままスカッシュマージのコードパスに混入していたことだ。デプロイメントを安全にするための仕組みそのものが、安全側に倒れていなかった。
COOデイグルは騒動の渦中、X上でこのインシデントを「edge case(エッジケース)」と表現した。テストでカバーされていなかった例外的なケース、という意味だ。だがマージキューとスカッシュマージの組み合わせは、大規模な開発組織がほぼ標準で使う構成だ。Mergifyは公開ブログで、これを「マージキューが沈黙のまま壊れた最悪の失敗モード」と評している。SLAは緑のまま、コミット履歴だけが間違っている。これがエッジケースか、と問えば、答えは難しい。
Zipline LabsのCTOライアン・オクセンホーンはX上で、「@GitHubはひどい不具合を出したうえに、影響を受けたリポジトリやプルリクエストを特定するためのサポートをまったく提供していない。今もまだ後始末をしている」と書いた。GitHubは「対象顧客全員に修復手順を送付した」と説明しているが、現場の体感は別物のようだ。
4月27日、Elasticsearchが落ちて検索が止まった
23日からわずか4日後の4月27日、別のインシデントが発生した。今度は検索系だ。
問題が起きたのはElasticsearch(Elastic社の検索エンジン)クラスタで、これはプルリクエスト・Issues・プロジェクトの検索を裏で支えるサブシステムだ。フェドロフはブログで、クラスタが過負荷で応答を返さなくなったと説明している。過負荷の引き金は ボットネット攻撃 の可能性が高い、と書かれた。
ステータスページのタイムラインを見ると、UTC16:39頃からPackagesの劣化、続いてIssues、Pull Requests、Actionsワークフロー実行が断続的に失敗した。Git操作とAPIは生きていたが、検索結果に依存するUI部分は空白を返した。Issuesの検索ができない状態は、運用チームから見るとシステムの一部が消えたに等しい。
フェドロフはこのサブシステムについて、率直に書いている。「これはまだ単一障害点として完全には分離できていなかったシステムのひとつだ。他の領域がリスク優先度の上位に来ていたためだ」。
つまり、4月の段階でも単一障害点になり得るサブシステムが残されていたことを、CTO自身が認めた。
「10倍計画」から「30倍計画」へ
このブログ投稿の重要な部分は、謝罪ではなく拡張計画の更新だ。
GitHubは2025年10月に、容量を 10倍に拡張する計画 の実行を開始した。失敗から復旧する力(フェイルオーバー)を含め、信頼性を抜本的に改善する狙いがあった。フェドロフによれば、2026年2月の時点で「 30倍前提で設計し直す 」必要があるとわかった。半年も経たないうちに、見積もりを3倍に書き換えている。
理由は、2025年12月後半から急加速したエージェント型開発ワークフローだ。AIが自律的にリポジトリを作り、プルリクエストを送り、APIを叩く。フェドロフが本文中で挙げた指標は、リポジトリ作成、プルリクエスト数、API利用、自動化、大規模リポジトリのワークロードと、ほぼ全方位だ。
GitHubが本文中で公開しているグラフでは、月あたりプルリクエスト9,000万件、コミット14億件、新規リポジトリ2,000万件といった数字が示されている。2023年から2025年までは緩やかな立ち上がりだったが、2025年後半から急峻な指数曲線に変わっている。
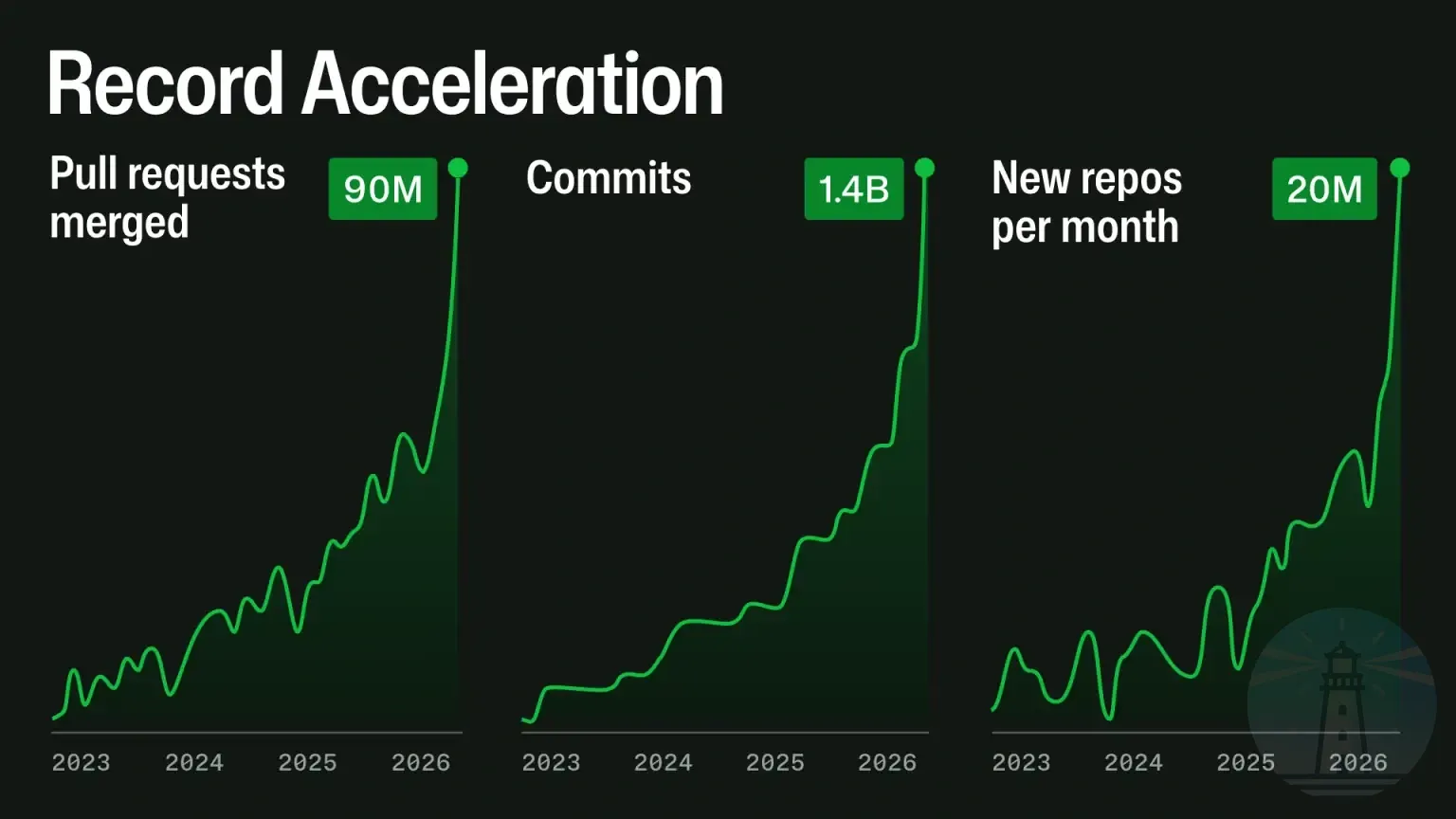
エージェントが動く時代には、人間が手で押すボタンとは桁の違うトラフィックが流れる。10倍では足りなかった、というのはたぶん本当のことだ。
短期で潰した壁、長期で引きずる壁
ブログの「What we're doing(今やっていること)」には、短期と長期の対策が混在して並んでいる。
短期で対処した内容として挙げられているのは、Webhookの基盤をMySQLから別バックエンドへ移すこと、ユーザーセッションキャッシュの再設計、認証・認可フローの改修によるデータベース負荷軽減、そしてAzureを活用したコンピュートの増強だ。要は「ボトルネックが想定より早く出てきたので、慌てて潰した」という話だ。
そのうえで、より構造的な作業として書かれているのが、gitとGitHub Actionsを他のワークロードから分離する話、依存関係とトラフィック階層を仔細に分析して 爆発半径 を最小化する話、そしてパフォーマンスやスケールに敏感なコードをRubyモノリスからGoへ移す話だ。
性能やスケール感度の高いコードを、Rubyモノリスから外に切り出してGoで書き直す作業を加速させた。
——GitHub公式ブログより要約
長年GitHubを支えてきたRubyモノリスからの脱却が、ここまではっきり書かれたのは異例だ。Rubyを否定する話ではないが、構造的に外せないボトルネックがそこに残っている、と読み取るのが自然だ。
加えてフェドロフは、自社運用の小規模データセンターからパブリッククラウドへの移行に加え、 マルチクラウド化 への道筋を引き始めたことも明かした。Azureに集約する戦略だけでは、必要なレジリエンスとレイテンシを将来確保できない、という判断だ。
透明性は、ステータスページから始まる
最後に、ブログは透明性についての改善にも触れている。
GitHubは最近、ステータスページに可用性の数字を含めるよう更新した。これまでバラバラだったインシデント表示を統一し、大小を問わず障害を明示するように方針を変えた、と書かれている。「問題が自分側にあるのかGitHub側にあるのかを推測しなくて済むようにする」という言い方は、それまではユーザー側に推測を強いていた、という告白でもある。
非公式の再構築版ステータスページが、公式に出てこない数字を掘り起こしてきた構図は、これまで何度か指摘されてきた。今回の更新は、その圧力に対する公式の回答だ。
ただ、エンドユーザーが本当に必要としているのは数字の追加ではなく、「何が壊れていて、何分で直るのか」の確度だろう。マージキューの破綻が3時間半検知されないシステムでは、ステータスページに数字を足しただけでは届かないところに、信頼性の問題が残る。
エンタープライズの判断材料が変わる
開発インフラとしてのGitHubは、ある時期まで「壊れない」前提で組み込まれてきた。CIに繋がり、本番のデプロイに繋がり、エンタープライズのワークフローに溶け込んできた。今回のCTO声明は、その前提を 「もう普通に壊れる」 に更新する材料になる。
エンタープライズのリスク管理担当者は、これからの数四半期、3つの問いに向き合うことになりそうだ。マージキューが沈黙したまま壊れる可能性に、どう備えるか。検索が単一障害点として残るサブシステムに、社内のどの動線が依存しているか。そして、Azure依存とマルチクラウド化のあいだで、どこに自社の冗長性を置くか。
GitHubは大きすぎて代替が難しい。だからこそ、壊れ方を知っておく価値が出てきた。
CTOの謝罪文を読んだとき、ぐらつくのは信頼ではなく、「依存していい範囲」の輪郭のほうかもしれない。
参照元
他参照
- The Stack - GitHub bug messed up customer code; COO plays down incident
- Mergify - A merge queue is critical infrastructure. Build it accordingly.
関連記事
- Azureの「構造的脆弱性」を元エンジニアが告発、人材軽視の代償
- Outlook.com世界規模で認証障害、変更を切り戻し中
- Microsoft、Azure LinuxをFedoraベースに刷新へ
- Windows Server過剰請求、英国で約4500億円訴訟が前進
- GitHub Copilot、新規受付停止とトークン課金化へ
- Microsoft 365 管理センターが再びダウン、皮肉な構造が露わに
- Outlook障害、iPhoneユーザーに再認証を強いる事態
- Outlookアカウント、正しいパスワードでも締め出される
- GitHub Copilot、6月1日に従量課金へ全面移行
- OpenAIとマイクロソフト、AGI条項が事実上消えた日



