
MacでNVIDIA復活、TinyGPUドライバの実力と現実
2019年以来、MacでNVIDIA GPUを動かすことは不可能だった。その壁が、たった今崩れようとしている。


2019年以来、MacでNVIDIA GPUを動かすことは不可能だった。その壁が、たった今崩れようとしている。
7年間の空白を埋めたのはAppleでもNVIDIAでもない
MacでNVIDIA GPUが動いている。仮想マシン経由でもなく、ハック経由でもない。Thunderbolt越しにGPUと直接通信する、Apple公認のオープンソースドライバを通じて。
2026年3月31日、ジョージ・ホッツ(George Hotz)率いるTiny Corpが、macOS向けGPUドライバ「TinyGPU」のApple承認を発表した。iPhoneの初代脱獄やPS3のハッキングで知られるホッツが創設したこの小さな企業が、時価総額数兆ドル規模の2社がどちらも手を付けなかった問題を、力業で解決してみせた形だ。
TinyGPUはAppleのDriverKitフレームワークを通じて正式に承認されており、SIP(システム整合性保護)の無効化は不要だ。
事の発端は2018年に遡る。AppleはmacOS MojaveでNVIDIAの新しいGPUドライバサポートを事実上打ち切った。NVIDIA側は「Appleがドライバを承認しない限りリリースできない」と公式に声明を出し、両社の関係は完全に冷え切った。2020年にApple Siliconへ移行した際には、eGPUサポート自体がIntel Mac限定のまま置き去りにされている。
つまり、約7年間にわたって「MacでNVIDIA GPU」は存在しなかった。それを変えたのが、TinyGPUだ。
ドライバの仕組みと対応環境
TinyGPUはmacOSのカーネル拡張として動作し、外部GPUをThunderboltまたはUSB4経由でAIコンピュート専用デバイスとして認識させる。ゲームのグラフィックス描画やディスプレイ出力には対応しない。Metal APIとも無関係だ。あくまで AIワークロード専用 のコンピュートドライバである。
対応環境はmacOS 12.1(Monterey)以降、Thunderbolt 3/4またはUSB4ポート搭載のApple Silicon Mac。GPU側はAMD RDNA3世代以降、NVIDIAはAmpere世代(RTX 30シリーズ)以降が対象となる。
AMDのGPUはネイティブに動作する一方、NVIDIA GPUではDocker Desktopを介したNVCCコンパイラのセットアップが必要だ。とはいえ、セットアップは拍子抜けするほど簡単だという声が多い。curlコマンド1本でインストールし、システム設定でドライバ拡張をオンにするだけ。
Tiny Corpは公式Xアカウントで「Qwenでもインストールできるくらい簡単で、そのままQwenを動かせる」と自信を見せている。
ベンチマークが突きつける現実
ここからが正直なところだ。YouTuberのアレックス・ジスキンド(Alex Ziskind)がMac Mini(M4 Pro、メモリ64GB)にBlackwell世代のRTX 5060 Ti、5070 Ti、RTX 5090を接続して実測した結果は、期待と現実のギャップをはっきり見せてくれる。
行列演算:GPUの地力は出ている
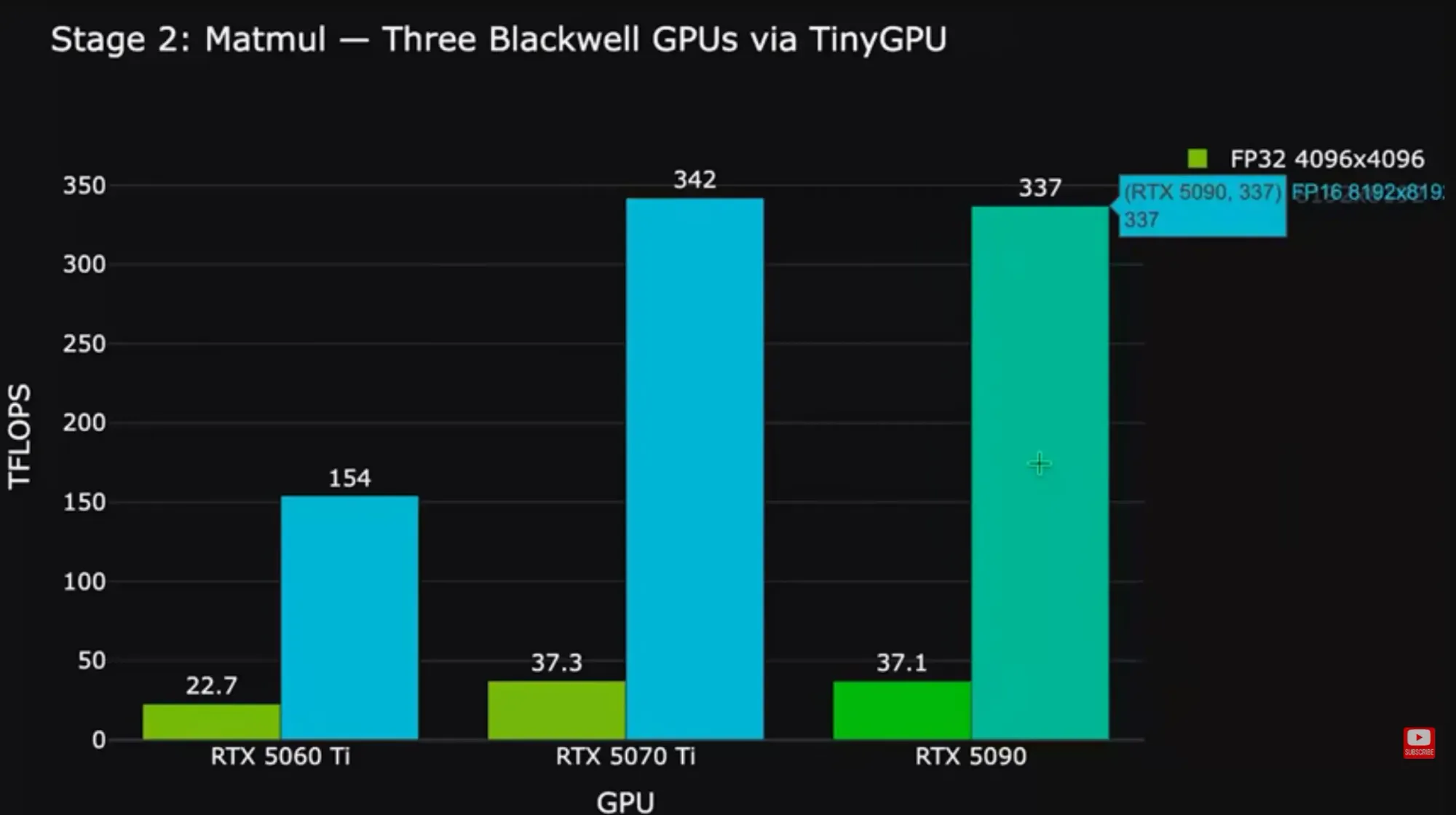
FP32の行列乗算ベンチマークでは、RTX 5060 Tiが22.7 TFLOPS。M4 Proの内蔵GPUが約33 TFLOPSでこれを上回ったのは少し驚きだが、RTX 5070 Tiは8K×8K行列で 342 TFLOPS を記録し、5060 Tiの2倍以上を叩き出した。RTX 5090は5070 Tiとほぼ同等のスコアにとどまったものの、 32GBのVRAM が活きる場面が別にある。
LLM推論:速いが、遅い
tinygrad内蔵ベンチマークでQwen3 8Bを実行した結果、RTX 5090で約6トークン/秒。5060 Tiが4.6、5070 Tiが5.5、M4 ProのMetal GPUが3.66トークン/秒だった。外部GPUはいずれもMetal内蔵GPUを上回っている。
RTX 5090の32GB VRAMを活かし、より大きなモデルも試されている。Qwen 2.5 14Bで3.75トークン/秒、Llama 3.1 8B(INT8量子化)で7.48トークン/秒。使えなくはないが、感動するような数字でもない。
ここで注目すべきは、RTX 5090のメモリ帯域幅だ。スペック上は1.79TB/秒だが、ジスキンドの計測では実効28.8GB/秒しか出ていない。本来の性能の約1.6%しか引き出せていない計算になる。
llama.cppとの比較:10倍の差
同じモデル、同じ条件で比較したとき、llama.cppのMetal実装はTinyGPU+RTX 5090の 約10倍 高速だった。Metal上のtinygradとの比較では18倍。最初のトークンが返ってくるまでの時間も、llama.cppの651ミリ秒に対してtinygradは約5秒と大きく水をあけられている。
llama.cppには何年もかけて手作業で最適化されたMetalカーネル、量子化対応の行列演算融合、KVキャッシュ管理の蓄積がある。tinygradは汎用コンパイラからカーネルを自動生成しており、推論速度でllama.cppに対抗することは現時点での目標ではない。
Thunderboltはボトルネックではない
「Thunderbolt経由だから遅いのでは」という疑問は自然だが、LLM推論においてはほぼ無関係だ。モデルの重みは起動時に一度だけGPUのVRAMに転送され、以降のトークン生成はGPU内部で完結する。Thunderboltケーブルを通過するデータは1トークンあたり数バイトに過ぎない。
ボトルネックは明確にtinygradの カーネル効率 だ。RTX 5090のメモリが毎秒1.79TBを流せるのに、実際には毎秒33GBしか使えていない。ケーブルの問題ではなく、ソフトウェア最適化の問題であり、今後改善される余地は膨大に残っている。
重要なのは速度ではない
ここまで読んで「遅いなら意味がない」と思った人もいるかもしれない。だが、この話の核心はベンチマークの数字ではない。
Tiny Corpがやったことの本質は、NVIDIAのGPUドライバをゼロから書き、オープンソースのmacOSカーネル拡張として実装し、Blackwell世代のGPUをApple Silicon上でThunderbolt経由で動かしたことだ。1年前には不可能だったことを、時価総額数兆ドルの2社が拒否し続けた問題を、コミュニティプロジェクトが実現した。
ドライバ、コンパイラパイプライン、メモリマネージャーという「難しい部分」はすでに完成している。カーネルの最適化は時間が解決する類の問題だ。
ゲーマーには朗報ではない
ただし、誤解してはいけない。TinyGPUはゲームには使えない。ディスプレイ出力もない。Metal API経由のグラフィックスアクセラレーションもない。macOSはこの外部GPUを純粋なコンピュートデバイスとしてのみ認識する。「MacでNVIDIA GPUが動く」という表現から連想するものとは、かなり違う現実だ。
コメント欄でも「ゲームはテストしないのか」という声が目立つが、そもそもアーキテクチャとしてゲーミング用途を想定していない。AI推論とML開発者向けの、限定的だが確実な前進だ。
Appleの壁に入った亀裂
AppleがTiny CorpのドライバをDriverKit経由で公式に承認したという事実は、技術的な成果と同じくらい重要な意味を持つ。Apple Siliconの統合アーキテクチャとMetal API中心の設計思想を考えれば、サードパーティのGPUコンピュートドライバを許可すること自体が異例の判断だ。
背景にはAI開発者からの圧力がある。CUDA環境へのアクセスを必要とするML開発者にとって、Apple純正のGPUとNeural Engineだけでは限界がある。クラウドGPUに逃げるか、Macを諦めるか——その二択を迫られてきた層に、TinyGPUは 第三の選択肢 を提示した。
とはいえ、Appleがこれを「壁の全面撤去」ではなく「管理された小さな亀裂」として許容したことも読み取れる。コンピュート限定、AI/MLワークロード限定。Appleの統合GPU戦略そのものを脅かさない範囲で、開発者コミュニティへの譲歩を見せた形だ。
7年間閉ざされていたドアが、ほんの少しだけ開いた。その隙間から何が生まれるかは、これからのカーネル最適化の進捗と、コミュニティの手に委ねられている。
参照元
関連記事
- Apple Silicon初のeGPU承認——NVIDIA対応だがAI研究限定
- 3万ドルのAI用GPUが約40万円のRTX 5090に惨敗する理由
- Exabox予約開始、約16億円コンテナ型AIスパコンの正体
- M5 Max MacBook ProのSSDが100℃超え──AI時代の「見えない熱問題」
- NVIDIA保証クレーム11倍、AIバブルの請求書が届いた
- DLSS Enablerがx5/x6解放、RTX 40も対象
- Apple、「AIを使わないチーム」を査定対象にし始めた
- CopprLink接続のeGPUがRTX 5090をほぼネイティブ速度で動かす
- NVIDIAが大手PC企業を買収交渉中 Dell・HP株急騰
- NVIDIAが明かした設計自動化の実像、80人月が一晩に



